


Double-Precision Floating Point Encoding
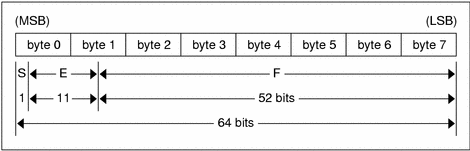
Just as the most and least significant bytes of an integer are 0 and 3, the most-significant and least-significant bits of a double-precision floating-point number are 0 and 63. The beginning bit, and most significant bit, offsets of S, E, and F are 0, 1, and 12 respectively.
These offsets refer to the logical positions of the bits, not to their physical locations, which vary from medium to medium.
Consult the IEEE specifications about the encoding for signed zero, signed infinity (overflow), and de-normalized numbers (underflow) [1]. According to IEEE specifications, the NaN (not a number) is system dependent and should not be used externally.
Quadruple-Precision Floating Point
The standard defines the encoding for the quadruple-precision floating-point data type quadruple (128 bits or 16 bytes). The encoding used is the IEEE standard for normalized quadruple-precision floating-point numbers [1]. The standard encodes the following three fields, which describe the quadruple-precision floating-point number.
S: The sign of the number. Values 0 and 1 represent positive and negative respectively. One bit.
E: The exponent of the number, base 2. Fifteen bits are in this field. The exponent is biased by 16383.
F: The fractional part of the number's mantissa, base 2. One hundred eleven bits are in this field.
Therefore, the floating-point number is described by:
(-1)**S * 2**(E-Bias) * 1.F |
Declaration
quadruple identifier; |
Quadruple-Precision Floating Point Encoding
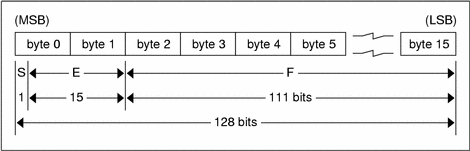
Just as the most-significant and least-significant bytes of an integer are 0 and 3, the most-significant and least-significant bits of a quadruple-precision floating- point number are 0 and 127. The beginning bit, and most-significant bit, offsets of S, E, and F are 0, 1, and 16 respectively. These offsets refer to the logical positions of the bits, not to their physical locations, which vary from medium to medium.
Consult the IEEE specifications about the encoding for signed zero, signed infinity (overflow), and de-normalized numbers (underflow) [1]. According to IEEE specifications, the NaN (not a number) is system dependent and should not be used externally.
Fixed-Length Opaque Data
At times, fixed-length uninterpreted data needs to be passed among machines. This data is called opaque.
Declaration
Opaque data is declared as follows.
opaque identifier[n]; |
In this declaration, the constant n is the static number of bytes necessary to contain the opaque data. The n bytes are followed by enough (0 to 3) residual zero bytes r to make the total byte count of the opaque object a multiple of four.
Fixed-Length Opaque Encoding
The n bytes are followed by enough (0 to 3) residual zero bytes r to make the total byte count of the opaque object a multiple of four.
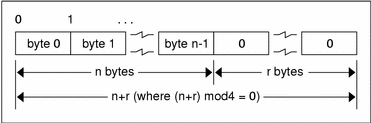
Variable-Length Opaque Data
The standard also provides for variable-length counted opaque data. Such data is defined as a sequence of n (numbered 0 through n-1) arbitrary bytes to be the number n encoded as an unsigned integer, as described subsequently, and followed by the n bytes of the sequence.
Byte b of the sequence always precedes byte b+1 of the sequence, and byte 0 of the sequence always follows the sequence's length. The n bytes are followed by enough (0 to 3) residual zero bytes, r, to make the total byte count a multiple of four.
Declaration
Variable-length opaque data is declared in the following way.
opaque identifier<m>; |
or
opaque identifier<>;; |
The constant m denotes an upper bound of the number of bytes that the sequence can contain. If m is not specified, as in the second declaration, it is assumed to be (2**32) - 1, the maximum length. For example, a filing protocol might state that the maximum data transfer size is 8192 bytes, as follows.
opaque filedata<8192>; |
Variable-Length Opaque Encoding
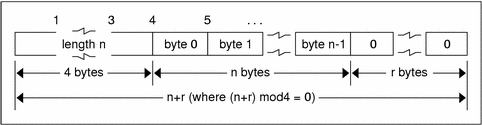
Do not encode a length greater than the maximum described in the specification.
Counted Byte Strings
The standard defines a string of n (numbered 0 through n-1) ASCII bytes to be the number n encoded as an unsigned integer, as described previously, and followed by the n bytes of the string. Byte b of the string always precedes byte b+1 of the string, and byte 0 of the string always follows the string's length. The n bytes are followed by enough (0 to 3) residual zero bytes r to make the total byte count a multiple of four.
Declaration
Counted byte strings are declared as follows.
string object<m>; |
or
string object<>; |
The constant m denotes an upper bound of the number of bytes that a string can contain. If m is not specified, as in the second declaration, it is assumed to be (2**32) - 1, the maximum length. The constant m would normally be found in a protocol specification. For example, a filing protocol might state that a file name can be no longer than 255 bytes, as follows.
string filename<255>; |
String Encoding
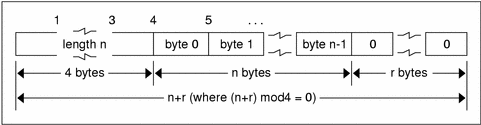
Do not encode a length greater than the maximum described in the specification.
Fixed-Length Array
Fixed-length arrays of elements numbered 0 through n-1 are encoded by individually encoding the elements of the array in their natural order, 0 through n-1. Each element's size is a multiple of 4 bytes. Though all elements are of the same type, the elements might have different sizes. For example, in a fixed-length array of strings, all elements are of type string, yet each element varies in its length.
Declaration
Declarations for fixed-length arrays of homogenous elements are in the following form.
type-name identifier[n]; |
Fixed-Length Array Encoding
Variable-Length Array
Counted arrays enable variable-length arrays to be encoded as homogeneous elements. The element count n, an unsigned integer, is followed by each array element, starting with element 0 and progressing through element n-1.
Declaration
The declaration for variable-length arrays follows this form.
type-name identifier<m>; |
or
type-name identifier<>; |
The constant m specifies the maximum acceptable element count of an array. If m is not specified, it is assumed to be (2**32) - 1.
Counted Array Encoding
Do not encode a length greater than the maximum described in the specification.
Structure
The components of the structure are encoded in the order of their declaration in the structure. Each component's size is a multiple of 4 bytes, though the components might be different sizes.
Declaration
Structures are declared as follows.
struct {
component-declaration-A;
component-declaration-B;
...
} identifier;
|
Structure Encoding

Discriminated Union
A discriminated union is a type composed of a discriminant followed by a type selected from a set of prearranged types according to the value of the discriminant. The type of discriminant is either int, unsigned int, or an enumerated type, such as bool. The component types are called "arms" of the union, and are preceded by the value of the discriminant that implies their encoding.
Declaration
Discriminated unions are declared as follows.
union switch (discriminant-declaration) {
case discriminant-value-A:
arm-declaration-A;
case discriminant-value-B:
arm-declaration-B;
...
default:
default-declaration;
} identifier;
|
Each case keyword is followed by a legal value of the discriminant. The default arm is optional. If the arm is not specified, then a valid encoding of the union cannot take on unspecified discriminant values. The size of the implied arm is always a multiple of 4 bytes.
The discriminated union is encoded as its discriminant followed by the encoding of the implied arm.