| SRDB ID | Synopsis | Date | ||
| 48873 | Sun Fire[TM] 12K/15K: Dstop: Command Pool Timeout | 26 Nov 2002 |
| Status | Issued |
| Description |
- Problem Statement/Title:
Dstop: Command Pool Timeout
- Symptoms:
This document is intended to lead the troubleshooter through the process
of diagnosing Command Pool Timeout Dstops which may occur within a Sun Fire
12K/15K domain. These Dstops are characterized by specific error signatures
reported by the redx 'wfail' output.
The criteria for the Command Pool Timeout signature are:
1. The Master SDI records at least one of the following as a first error:
CoreErr0[25]: D 1E Command pool timeout, non-split exp (M)
S0Err2[17]: D 1E Slot0 command pool timeout (M)
S1Err2[17]: D 1E Slot1 command pool timeout (M)
2. The Master SDI Dstop0 register records at least one of the following as
the first error (1E):
Dstop0[19]: D 1E SDI internal core requested Dstop
Dstop0[23]: D 1E SDI internal Slot0 port requested Dstop
Dstop0[24]: D 1E SDI internal Slot1 port requested Dstop
3. 'wfail' reports the following:
The FRU for this failure cannot be identified from the available information.
This error is not diagnosable. The FAIL action is just a guess to
satisfy the POST design requirement that something must be
deconfigured after a stop to guarantee that the process terminates.
The FAILed component is no more suspect than any other hardware
in the domain.
It is required that ALL the above criteria are met and criterion 1 and 2 are
reported within the SAME Master SDI. For example:
SDI EX16/S0 Dstop0[31:0] = 200C8008
SDI EX16/S0 Dstop0[31:0] = 200C8008
Dstop0[18]: D DARB texp requests Slot1 Dstop (M)
Dstop0[19]: D 1E SDI internal core requested Dstop
Dstop0[29]: D Slot1 asserted Error, enabled to cause Dstop (M)
SDI EX16/S0 Core_Error0[31:0] = 02008200 Mask = 0051FFFF
CoreErr0[25]: D 1E Command pool timeout, non-split exp (M)
valid_{slot_wr[1:0],read}_TO = 1 (rev 4+)
{cmd_pool_loc[5:0],cmd4io,retired,half_used} = 0A4
...
The FRU for this failure cannot be identified from the available information.
This error is not diagnosable. The FAIL action is just a guess to
satisfy the POST design requirement that something must be
deconfigured after a stop to guarantee that the process terminates.
The FAILed component is no more suspect than any other hardware
in the domain.
Here, EX16/SDI0 reports criterion 1 and 2, and the appropriate diagnistic
message from 'wfail' is present. SOLUTION SUMMARY:
- Troubleshooting:
ASSUMPTIONS
It is a basic assumption that the machine experiencing Command Pool Timeouts
is housed in a stable, data center quality environment. Consistent power,
temperature, humidity, and cleanliness of the system is important for computer
stability. Although there has never been an established link between an
environmental problem and a Command Pool Timeout specifically, an environment
which is not stable can cause failures in undetermined ways. Should these errors
arise in an unstable environment, the environmental deficiencies must be
addressed in parallel with this troubleshooting procedure.
It is also assumed that SCs are running SMS 1.2 or higher. Any at SMS 1.1 are
encouraged to upgrade.
TROUBLESHOOTING
Use the following flow diagram to assist in walking through the troubleshooting
process. A more detailed description of each step is after the diagram.
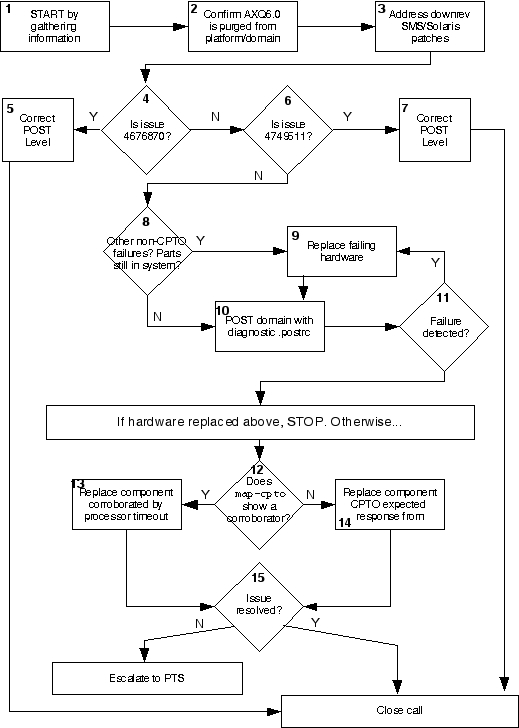
Step 1 Collect customer data including domain explorer, SC explorer and
recent Radiance cases/PTS Escalations
Step 2 FCO A0192-1 is the mechanism by which AXQ6.0 is purged from a system.
To determine if a domain/system has AXQ6.0s, use the 'shaxq' within
redx. An AXQ6.0 appears as follows:
redxl> shaxq 3
Note: Data is displayed from the currently loaded dump file.
AXQ EX3 (3) Component ID = C4312049 Rev 6.0
Step 3 Command Pool Timeouts are known to be caused by downrev patches. On
the SC, ensure SMS 1.2 patch 112488-10 (or higher) is installed. On the
domain, if Sun[TM] Dual Fast Ethernet and Dual SCSI/P Adapter (X2222A)
cards are present, ensure Solaris[TM] 8 patch 109885-08 (or higher) is
installed.
Step 4 Bug 4676870 is partially fixed in SMS 1.2 patch 112488-06 , and fully
fixed in 112488-07 (or higher). The fix is integrated into SMS 1.3 and
beyond. In order for a domain to be protected from 4676870 , it must have
been rePOSTed with the corrected POST patch. Explorer data can be used
to determine this.
Determine when the domain was last POSTed. A domain is considered POSTed when
one of the following "Cmdline" values appear in the post log:
/opt/SUNWSMS/SMS1.2/bin/hpost -d D
/opt/SUNWSMS/SMS1.2/bin/hpost -d D -Q
/opt/SUNWSMS/SMS1.2/bin/hpost -d D -a -Palt_level ##
% grep Cmdline sf15k/<Domain_ID>/adm/post/post*
post020817.1222.12.log:# Cmdline: /opt/SUNWSMS/SMS1.2/bin/hpost -d D -Q
post020903.0426.50.log:# Cmdline: /opt/SUNWSMS/SMS1.2/bin/hpost -d D -D
/var/opt/SUNWSMS/SMS1.2/adm/D/dump/dsmd.rstop.020903.0426.49 -y "DSMD
RecordStop Dump"
post020903.0426.58.log:# Cmdline: /opt/SUNWSMS/SMS1.2/bin/hpost -d D -W
post021030.0405.01.log:# Cmdline: /opt/SUNWSMS/SMS1.2/bin/hpost -d D -D
/var/opt/SUNWSMS/SMS1.2/adm/D/dump/dsmd.dstop.021030.0405.00 -y "DSMD
DomainStop Dump"
post021030.0406.34.log:# Cmdline: /opt/SUNWSMS/SMS1.2/bin/hpost -d D -a
-Palt_level 16
In this example, the last POST of the domain prior to the Dstop on Oct
30th was a -Q on August 17th. Next, determine the POST version at the time
of the last POST:
% grep "hpost version" sf15k/D/adm/post/post020817.1222.12.log
# hpost version 1.2 Generic 112488-06 Jun 18 2002 15:53:15
Use the matrix below to determine if the domain was vulnerable to 4676870 .
+--------------+----------------+----------------+
| | -Q POST | Non -Q POST |
+--------------+----------------+----------------+
| <= 112488-05 | Vulnerable | Vulnerable |
+--------------+----------------+----------------+
| = 112488-06 | Vulnerable | Not Vulnerable |
+--------------+----------------+----------------+
| >= 112488-07 | Not Vulnerable | Not Vulnerable |
+--------------+----------------+----------------+
Step 5 Install SMS 1.2 patch 112488-10 (or higher). If already installed, ensure
all domains in the platform have rePOSTed with at least 112488-07 ,
preferably 112488-10 (or higher).
Step 6 Bug 4761277 is fixed in SMS 1.2 patch 112488-10 (or higher). The fix is
integrated into SMS 1.3 and beyond. The following criteria must be met
if 4761277 is the cause:
1. Patch 112488-10 (or higher) is not installed.
2. The domain that Dstopped contains one or more split expanders. To
locate split expanders in the system, use the find-split-ex script
available from PTS at http://pts-americas.west/esg/hsg/starcat/tools.
3. Immediately prior to the Dstop (<10 seconds) another POST process
started on a domain that shares an expander with the domain that
Dstopped.
Refer to the bug for details and dump examples.
Step 7 Install SMS 1.2 patch 112488-10 (or higher).
Step 8 Identify any other recent domain failures. Failures include but are not
limited to:
o System panics
o Dstops that were not Command Pool Timeouts
o Power failures on system components (consult the platform log)
o Frequent and repeated RecordStops.
o Indicators of I/O path problems (SCSI retries, parity errors,
OBP probes, etc.)
Any of the aforementioned errors may be indicative of a hardware error
which, given a different set of circumstances, could result in a Command
Pool Timeout.
Step 9 Any Safari device diagnosed as suspicious or likely root cause of failures
noted in Step 8 can be considered a suspect for causing a Command Pool
Timeout. The suspect hardware should be replaced.
Step 10 A high level POST is the most effective diagnostic level that can be run
on a 12K/15K domain. To maximize coverage and stress areas known to have
caused Command Pool Timeouts, add the following entries to a .postrc file
prior to POSTing:
# BEGIN - directives for Command Pool Timeouts
level 64
# Stress procs/L2 SRAM, but not memory
phase_level cpu_lpost 1 96
phase_level cpu_lpost 3 96
phase_level cpu_lpost 4 96
It is suggested that the platform/domain .postrc files are not modified.
Rather, create a one-time .postrc file for Command Pool Timeout trouble-
shooting. For example:
% mkdir /var/tmp/sun
% cd /var/tmp/sun
% vi .postrc
<make above edits>
% setkeyswitch -d X on
Be sure to include any additional .postrc directives required by the
domain configuration. Also, be sure to remove the .postrc file after
troubleshooting is complete.
Step 11 If a failure occurs during the POST in Step 10, diagnose and replace the
indicated hardware, then repeat the Step 10 POST. Step 10 should be
repeated until it runs without error.
Step 12 As discussed in the Diagnostic Information section of this document, the
Command Pool Timeout indicates the component from which it expected a
response. In the best case scenario, the state dump will also have a
processor that was expecting a response from the same component. It
corroborates the SDI's expectation.
A script, map-cpto, has been written to streamline the procedure. It is
available from PTS at http://pts-americas.west/esg/hsg/starcat/tools.
Execute map-cpto against the state dump file as such:
% map-cpto dsmd.dstop.020302.0450.16
CPTO Expected Response From
--------- ----------------------------
EX4/SDI0 IO4 (assuming sane AXQ cmd)
Proc Timeout Destination Address
------ ------- -------------- ------------
SB3/P0 NCPQ_TO IO4/C3V1 402.4C00080_
In this example, we have a corroboration. EX4/SDI0 was expecting
response from IO4. Likewise, SB3/P0 had an Noncoherent Pending Queue
Timeout (NCPQ_TO) trying to transact with IO4/C3V1. The I/O card in
IO4/C3V1 is a prime suspect.
Another example of a corroboration for a system board:
% map-cpto dsmd.dstop.021030.0405.00
CPTO Expected Response From
--------- ----------------------------
EX10/SDI0 SB10 (assuming sane AXQ cmd)
Proc Timeout Destination Address
------ ------- -------------- ------------
SB10/P2 CPQ_TO EX10 (CASM 10) 141.F102DDE_
SB12/P0 CPQ_TO EX17 (CASM 17) 220.04D9A30_
SB12/P2 CPQ_TO EX17 (CASM 17) 221.FA8A3F2_
SB17/P1 CPQ_TO EX17 (CASM 17) 220.ED40870_
Here, we have EX10/SDI0 expecting response from SB10. Also, SB10/P2
had a Coherent Pending Queue Tiemout (CPQ_TO) trying to transact within
EX10. Since this is a cacheable transaction, it is possible that either
SB10 or IO10 owned the cache line being sought, but it is a higher
probability that SB10 owned the cache line. Another note is that it
cannot be assumed that SB10/P2's transaction resulted in the Command
Pool Timeout. It is equally plausable that SB17/P1's transaction went
to EX17, but EX17 determined that a valid copy of the cache line was
within EX10.
A corroboration is a confidence builder, not a guarantee of culpability
for a given component. In general, a corroborating NCPQ_TO yields a
higher confidence than a corroborating CPQ_TO.
However, corroborations do not always occur. Another example:
% map-cpto dsmd.dstop.021009.0955.59
CPTO Expected Response From
--------- ----------------------------
EX9/SDI0 IO9 (assuming sane AXQ cmd)
In this case, no associated processor timeouts were found in the state
dump. The only information available is what the SDI expected to happen.
Step 13 Replace the component corroborated by a processor timeout (NCPQ_TO
or CPQ_TO).
Step 14 Lacking any corroborating evidence, replace the component the SDI
expected to supply data.
Step 15 Monitor the system. If Command Pool Timeouts persist, escalate to PTS.
- Additional background information:
BACKGROUND INFORMATION
During system operation, the AXQ provides data commands to the SDI that instruct
the master SDI as to what it should do in a particular data transfer based on
the data MTag values. These commands are provided to the SDI as soon as the AXQ
formulates them. The data commands are stored in the Master SDI's data path
command pool. The data transfer associated with the command is in the form of a
WDTransID from a Slot 0/1 board connected to the SDI. When the data arrives, the
SDI pairs up the WDTransID with the data command and then processes the transfer.
It is not required (nor guaranteed) that the data command arrive prior to the
WDTransID, or vice verca. Thus, the SDI must hold the data commands and/or
WDTransIDs until a pairing can be made. When either the data command or the
WDTransID arrives in the SDI, a timeout counter is started. If the timeout
expires before a WDTransID/ data command pairing can be made, a Command Pool
Timeout results.
While, at first glance, it would appear that in all cases the device causing the
Command Pool Timeout is localized to the boardset reporting the failure. However,
closer examination reveals that this is untrue. For a read transaction, a device
issues an address request to the AXQ. Either the AXQ knows which device has the
data or searches for it. Suppose the AXQ believes device X has the data, but
device X disagrees with the AXQ. Device X will simply not provide the data and
the SDI, which was told by the AXQ to expect data from device X, times out. Thus,
read transactions are undiagnosable.
In contrast, for a write transaction, device X issues a write request to the AXQ.
The AXQ prepares for the write and then tells the device X it can send data. The
AXQ does this by transmitting TtransID/TargID data to the X. At this point, device
X has asked to write and the AXQ has confirmed the request. Next, the AXQ formu-
lates the data path command and issues it to the SDI. If device X fails to send
the data, the SDI times out. Because of the earlier exchange between X and the AXQ,
it is known the data path command is valid. Device X is at fault since it requested
to write but failed to send the data. Thus, Command Pool Timeouts on write trans-
actions can be isolated to a Slot 0/1 board, and 'wfail' diagnoses them as such.
As writes are diagnosable, they are not discussed further in this document.
POSSIBLE CAUSES
There are many possible hardware and software root causes for Command Pool
Timeouts. It is also quite possible there are more, as yet unidentified, root causes
which are not accounted for in this document.
Since these errors are dependent on sound behavior of Safari devices, these are
the principle hardware entities suspected to cause Command Pool Timeouts. This
includes CPUs, I/O Controllers, and their associated I/O interface cards. However,
as the data path command requires error free communication between the AXQ and
the SDI, an expander is a potential cause, although it is of lower probability.
The following components have been known to cause Command Pool Timeouts:
o Presence of X2222A card without patch 109885-08 (or later)
o Processors that (intermittently) fail POST with one or more of the following
errors:
- E$ ECC Tag Compare error
- E$ RAM Compare error
- Read returned wrong value
o Seating of PCI Adapters
o Bugs 4676870 , 4749511
o AXQ 6.0 (or lower)
DIAGNOSTIC INFORMATION
Dstop state dumps provide a frozen snapshot of the 12K/15K ASICs and interconnects.
However, since the ASICs and interconnects are frozen, it is not possible to dump
system memory states as with a panic dump. The majority of processor state is also
unavailable, unlike heartbeat or watchdog failures. The lack of such information
makes identification of the root cause solely dependent on data in the state dump.
For Command Pool Timeouts, sufficient information is not present in the state dump
to make a conclusive diagnosis of root cause. However, in some cases, there are
clues.
Command Pool Timeouts are reported by the SDI on an Expander. However, the
reporting SDI/Expander are generally victims of the error. Therefore, any conclusion
which defines an action of replacing and/or removing the reporting Expander should
NOT be executed until all other possible resolutions have been investigated.
When the SDI detects a Command Pool Timeout, it captures some failure information.
The capture data is sometimes useful in assisting with diagnosing Command Pool
Timeouts. The capture information is displayed in redx as follows:
SDI EX03/S0 Slot1_Error2[31:0] = 00028002 Mask = 7FFCFFFF
S1Err2[17]: D 1E Slot1 command pool timeout (M)
----> valid_{slot_wr[1:0],read}_TO = 1 (rev 4+)
----> {cmd_pool_loc[5:0],cmd4io,retired,half_used} = 024
The capture indicates if the transaction was a read or write. The first capture
line designates read when a value of 1 and write when 2 or 4. This example is a
read, thus undiagnosable.
The second capture indicates from which L1 board the SDI expected a response.
Bit [2] 'cmd4io' is the indicator. If clear (0), the SB was expected to respond.
If set (1), the IO was expected to respond. Remember that the least significant
digit in the capture must be expanded to binary. In this example, this digit is 4,
or 0100 in binary. Thus, bit [2] = 1. IO3 was expected to respond.
Additionally, in most cases, processor timeouts are present in the state dump.
When the hardware takes steps to freeze the ASICs, the Address Repeaters (ARs) on
the L1 boards are paused. Address arbitration ceases, effectively stopping all
transactions in the domain. However, if a processor had initiated a transaction
prior to the freeze, it will eventually error and/or timeout. Typical processor
errors that accompany Command Pool Timeouts as reported by redx 'shproc' are:
EmuSh[66]: CPQ_TO: Coherent Pending Queue Safari timeout.
EmuSh[57]: NCPQ_TO: Noncoherent Pending Queue Safari timeout.
EmuSh[56]: AID_LK: ATransID leakage error. Remote trans R_* issued
by proc, but reissued trans unable to complete.
CPQ_TOs and NCPQ_TOs are of interest, because the AFAR captured by the processor
contains a valid physical address. This address can be decoded to determine the
physical location (Expander/Board) of the address (redx's 'parse pa' command).
Such an address may corroborate the component the SDI reporting the Command Pool
Timeout expected a response from.
The AID_LK error is not of interest for Command Pool Timeouts. It is an indication
that the processor attempted to initiate a transaction, but was unable to win
address arbitration. It is likely this occurred after the AR was paused as part
of the Dstop process.
FEEDBACK
This document strives to identify and describe all known root causes for Command
Pool Timeouts. As a result, this document will be web available and may be modified
at any time. If there is evidence that a customer's Command Pool Timeout
experience is not covered by this document, escalate the case to PTS for further
review.
- Keywords
15K, 12K, SF15K, SF12K, Sun Fire 15K, Enterprise, Server, Sun Fire 12K,
Dstop, Command Pool Timeout
INTERNAL SUMMARY:
SUBMITTER: Scott Davenport BUG REPORT ID: 4676870, 4676870, 4676870, 4761277, 4761277, 4676870, 4749511 PATCH ID: 112488-10, 109885-08, 112488-06, 112488-07, 112488-10, 112488-07, 112488-10, 112488-10, 112488-10, 112488-10, 109885-08 APPLIES TO: Hardware/Sun Fire /15000, Hardware/Sun Fire /12000 ATTACHMENTS: