Sun Enterprise 10000 SSP 3.5 User Guide 10000 SSP 3.5 User Guide
|
|
| Sun Enterprise 10000 SSP 3.5 User Guide
|
|
| C H A P T E R 8 |
SSP Failover |
SSP provides an automatic failover capability that switches the main SSP to the spare within several minutes of detecting a failover condition, without operator intervention. A failover condition is a point of failure that occurs between the main and spare SSP, their control boards, or their network connections. The automatic failover mechanism continuously monitors both SSPs and their related components to detect a failover condition.
Required main and spare SSP architecture
How to maintain a dual SSP configuration for failover purposes
How to maintain a single SSP configuration
How automatic failover works
|
Note - You can have SSP failover, control board failover, or both. For information on automatic failover for control boards, see Chapter 9. For details on how the SSP, control board, and hub components must be configured for the various types of failover (SSP failover, control board failover, or both), refer to the Sun Enterprise 10000 SSP 3.5 Installation Guide and Release Notes. |
For automatic SSP and control board failover to function properly, you must set up your dual SSP configuration as illustrated in the following figure.
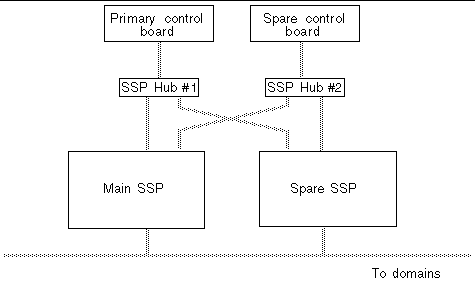
FIGURE 8-1 shows the SSP, control board, and hub configuration required for dual SSP and control board failover (two SSPs, two hubs, and two control boards). Refer to the Sun Enterprise 10000 SSP 3.5 Installation Guide and Release Notes for details on the other configurations (for example, you can have a single SSP configuration with two control boards) supported by the failover feature and the prerequisites for implementing automatic failover.
To maintain a dual SSP configuration for failover purposes, note the following:
The spare SSP must be properly configured to function in the same way as the main SSP within the network.
The main and the spare SSP must run the same version of the SSP software.
You can run certain types of third-party applications on your SSPs, provided that your SSPs meet the OpenSSP requirements described in the SSP 3.5 Installation Guide and Release Notes .
For automatic failover:
If you have user-created files on the main SSP that need to be maintained on the spare SSP for failover purposes, you must identify those files in the data propagation list.
This data propagation list determines which user-created files on the main SSP are to be automatically copied to and updated on the spare SSP, as part of the data synchronization process. For details on controlling this list, see Managing Data Synchronization .
If you have user-created commands that run on the main SSP, you must prepare those user commands for failover recovery, as explained in Performing Command Synchronization .
If you have user commands that require specific files for processing, be sure to add those files to the data propagation list.
Any changes that you make to the main SSP must be made to the spare SSP as well.
If failover is disabled or a failover occurs, and you change the SSP configuration, you must immediately run ssp_backup (1M) on the main SSP to create an SSP backup file. To successfully switchover to the spare SSP if the main SSP crashes, you must have a backup file that can be restored on the spare SSP.
In single and dual SSP configurations, the SSP configuration files are copied to the
/tmp
directory for data synchronization purposes. (For information on data synchronization, see
Managing Data Synchronization
.) However, for single SSP configurations it is suggested that you run the
setdatasync clean
command on a regular basis to reduce the number of SSP message and log files that accumulate in the
/tmp
directory. For additional details on using the
setdatasync clean
(1M) command, see
To Remove the Data Propagation List
and the
setdatasync
(1M) man page.
Automatic failover of the main to the spare SSP is accomplished through the following:
Failover monitoring
Failover monitoring is performed by the fod daemon, which continuously monitors the components in a dual SSP configuration for failure conditions. When a failover condition is detected, the fod daemon, in conjunction with the ssp_startup daemon, actually initiates the failover from the main SSP to the spare.
For details on the fod daemon and the various failure conditions that it detects, see Chapter 10 .
Data synchronization
For failover purposes, data on the main SSP must be synchronized with data on the spare SSP. The data synchronization daemon, datasyncd (1M),ensures that all SSP configuration files and specified user-created files (identified in the data propagation list) are copied from the main SSP to the spare, so that both SSPs are synchronized when a failover occurs. For further information on the datasyncd daemon, see Chapter 10 .
This data synchronization occurs whenever the SSP configuration or user-created files change on the main SSP, failover is enabled initially, or a data synchronization backup occurs. For details on data synchronization backup, see To Synchronize SSP Configuration Files Between the Main and the Spare SSP .
When a change to an SSP configuration file occurs, the change is propagated immediately to the spare SSP, except for the ssp_resource (4) file and the COD license file, which are checked once every minute and then propagated if they have changed.
Any change to a user-created file is propagated to the spare SSP at the time interval designated through the setdatasync(1M) command.
You control the data synchronization process using the setdatasync (1M) command, as described in Managing Data Synchronization .
Command synchronization
The recovery of user-defined commands interrupted by an automatic failover is called command synchronization. You use synchronization commands to indicate how these user commands are to be rerun on the new main SSP after a failover. For details on controlling command synchronization, see Performing Command Synchronization .
Floating IP address
The working main SSP is identified by a floating IP address that you assign during SSP installation or upgrade. This floating IP address is a logical interface that eliminates the need for a specific SSP host name to communicate between the Sun Enterprise 10000 domains and the main SSP. When a failover occurs, the floating IP address identifies the new main SSP. The floating IP address enables communication between the external monitoring software and the working main SSP.
The following sections provide an overview of the basic SSP failover situations and the various ways to control automatic failover.
An automatic failover is triggered when a failure in the dual SSP configuration affects the proper operation of the main SSP. Failure points can be caused by the following:
Failed network connections
SSP system failure due to a
Resource depletion
Resource depletion refers to the insufficient amount of disk space and virtual memory needed to perform SSP operations. If these resources drop below a certain threshold, the fod daemon initiates a failover. These resources are stored in the ssp_resource (4) file and can be modified using the setfailover command. For details, see To Modify the Memory or Disk Space Threshold in the ssp_resource File .
However, note that failover will not occur when it has been disabled by operator request or when certain failure conditions prevent the failover. The various failure conditions and the resulting failover actions are summarized in Chapter 10 , which identifies and explains the different points of failure detected by the failover process.
After a failover occurs, you can obtain failover status information by running the showfailover (1M) command on the working SSP. For details, see Obtaining Failover Status Information . Note that the failover status information displayed reflects the failover state at the time you run the showfailover command.
The following state changes occur after an SSP failover:
The initial failover state is Failed , which indicates that a failover occurred.
The failover state changes to Disabled when the working SSP recognizes that the other SSP or its connections are no longer functioning. As a result, the failover feature is disabled.
If you run showfailover at this point and review the output, you will probably find that the states for the various connection links are listed as FAILED , indicating that the connections are not working properly.
When the disabled SSP and its connections are restored, the failover state returns to Failed .
The failover feature is not working, even though both SSPs and their connections are working properly. If you run showfailover again and review the output, you will probably find that the states for all connection links are described as GOOD, which indicates that the SSPs and their connection links are functioning. At this point, you must re-enable automatic failover, as described in To Enable SSP Failover .
The SSP failover capability is automatically enabled upon SSP installation or upgrade. You control the failover state through the setfailover (1M) command, which enables you to do the following:
Disable, enable, or force an SSP failover.
View or set the memory or disk space thresholds in the ssp_resource file.
1. As user ssp on the main SSP, type:
SSP failover remains disabled it until you enable it, as explained in the next procedure.
|
Note Note - If you reboot both the main and spare SSP, failover is automatically re-enabled. |
2. Run the showfailover (1M) command to verify that failover was disabled.
For details, see Obtaining Failover Status Information . The failover state should be listed as Disabled .
When you use the setfailover (1M) command to enable failover after it has been disabled, the connection states are checked before failover is enabled. All connection links must be functioning properly before failover can be enabled. If any failed connections exist, failover is not enabled.
1. As user ssp on the main SSP, type:
SSP failover is enabled if both SSPs and all their connection links are working.
2. Run the showfailover (1M) command to verify that failover was enabled.
For details on reviewing the failover state and connection status, see Obtaining Failover Status Information .
|
Note Note - Wait several minutes before verifying the failover state. During this time, the setfailover command checks the control board connections before activating SSP failover. |
|
Note Note - Before forcing an SSP failover, be sure that both the main and spare SSP are synchronized. Use the showdatasync(1M) command to review the status of data synchronization between the main and spare SSP. For details, see Obtaining Data Synchronization Information. |
1. As user ssp on the main SSP, type:
The setfailover command checks the data synchronization state before forcing a failover. The forced failover will not occur if any of the following conditions exist:
A data synchronization backup, referred to as an active archive, is currently being performed.
A file is being propagated from the main SSP to the spare SSP.
One or more files exist in the data synchronization queue.
You can run the showdatasync (1M) command to obtain information on the synchronization state.
2. Run the showfailover (1M) command to verify that the forced failover occurred and review the failover state and connection status.
For details, see Obtaining Failover Status Information .
3. Re-enable SSP failover, as explained in To Enable SSP Failover .
|
|
When memory or disk space resources drop below a certain threshold, a failover occurs. However, you can change the threshold for these resources, which are stored in the ssp_resource (4) file, by using the setfailover (1M) command.
1. As user ssp on the main SSP, do one of the following:
To change the memory threshold, type:
where memory_threshold is the updated virtual memory value in Kbytes.
To change the disk space threshold, type:
where disk_space_threshold is the updated disk space value in Kbytes.
2. Verify the updated threshold value by using the setfailover (1M) command with only the -m or -d option.
Use the showfailover (1M) command on the main SSP to display failover status information. The following example shows the failover information displayed.
The failover status includes the
Failover state
The failover state is one of the following:
Active -- automatic failover is enabled and functioning normally
Disabled -- automatic failover has been disabled by operator request or by a failure condition that prevents a failover from occurring
Failed -- a failover occurred
After a failover, the status is listed as Failed until you re-enable failover using the setfailover (1M) command. You must manually re-enable failover, even after you have fixed all connections and they are identified as GOOD in the failover connection map (explained below).
Be aware that the failover state undergoes several changes after a failover occurs. For details, see SSP Failover State Changes .
Failover connection map
The connection map provides the status of the control board connection links monitored by the failover processes. A connection link is either GOOD, which means the connection is functioning properly, or FAILED, which indicates the connection is not working.
If you have failed connections, use this connection map to help determine the failure condition. For additional details on the failure conditions associated with the various failure points, see Description of Failover Detection Points in Chapter 10 .
SSP/CB host information
The host information section identifies the SSPs, control boards, and the control board that manages the JTAG interface and system clock.
You can also obtain information about the role of the current SSP by specifying the showfailover (1M) command with the -r option. The SSP role is either UNKNOWN (SSP role has not been determined), MAIN, or SPARE.
For additional details on the showfailover (1M) command, see the showfailover (1M) man page.
The data synchronization process copies any changes to the SSP configuration or specified user files on the main SSP to the spare SSP. As part of this process, the files to be copied are listed in a data synchronization queue so that you can see which files will be copied from the main to the spare SSP. You can use the showdatasync (1M) command to see which files are in the queue.
If you have user-created files (non-SSP files that are not contained in the SSP directories) that must be maintained on the spare SSP for failover purposes, you must identify these files in a data propagation list
(
/var/opt/SUNWssp/.ssp_private/user_file_list
). The
datasyncd
daemon uses this list to determine which files to copy from the main SSP to the spare.
By default, the data synchronization process checks for any changes to the user-created files on the main SSP every 60 minutes. You can use the setdatasync command to set the interval at which the data propagation list is to be checked for modifications (see To Add a File to the Data Propagation List ). The interval starts from the time at which a file is added to the data propagation list. The files in this list are propagated to the spare SSP only when they have changed from the last interval check.
|
Note Note - The data synchronization daemon uses the available disk space in the /tmp directory to copy files from the main SSP to the spare. If you have files to be copied that are larger than the /tmp directory, those files cannot be propagated. For example, if the data synchronization backup file (ds_backup.cpio) file gets larger than the available space in /tmp, you must reduce the size of this file before data propagation can occur. For details on reducing the size of the data synchronization backup file, see To Reduce the Size of the Data Synchronization Backup File. |
Use the setdatasync (1M) command to do the following:
Add a file to the data propagation list and indicate how often this file is to be checked for modifications.
Remove a file from the data propagation list.
Erase all entries and temporary files in the data propagation list and remove the data propagation list.
Push a file to the spare SSP without adding the file to the data propagation list.
Resynchronize the SSP configuration files between the main and the spare SSP.
For additional details, see the setdatasync (1M) man page.
 As user
ssp
on the main SSP, type:
As user
ssp
on the main SSP, type:
where interval indicates the frequency (number of minutes) that the specified filename is to be checked as part of the data synchronization process. The specified file name must contain the absolute path. The files on the data propagation list are copied to the spare SSP only when those files change on the main SSP, and not each time the files are checked.
As user
ssp
on the main SSP, type:
where filename is the file to be removed from the data propagation list. The file name must contain the absolute path.
The setdatasync clean command is useful for managing disk space in single SSP configurations, where the data propagation list can grow quite large and consume unnecessary disk space. It is possible for the /tmp directory to become full, which can cause the system to hang. You can run the setdatasync clean command as needed, either daily or weekly to prevent the /tmp directory from growing too large. Or, you can automate the cleanup by using the cron (1M) command with a crontab (1M) entry that uses the setdatasync clean command.
|
Note Note - Do not use this option when you have a dual SSP configuration because it can desynchronize data between the main and spare SSP. |
As user
ssp
on the main SSP, type:
As user
ssp
on the main SSP, type:
where filename is the file to be moved to the spare SSP without adding the file to the data propagation list. The file name must contain the absolute path.
|
|
Use this procedure to keep data between the main and spare SSP synchronized, for example, after SSP failover has been disabled then re-enabled. If you want to archive an SSP configuration, use the ssp_backup (1M) command.
As user
ssp
on the main SSP, type:
A data synchronization backup file ( /tmp/ds_backup.cpio ) of all SSP configuration data on the main SSP is created and then restored on the spare SSP. Note that the data synchronization backup differs from a backup created by the ssp_backup (1M) command:
The data synchronization backup, while similar to a backup created by the ssp_backup command, does not back up the /tftpboot directory.
The data synchronization backup does not restore the following files:
The data synchronization backup can fail if the backup file exceeds the available disk space in the /tmp directory. For details on reducing the size of the data synchronization backup file, see the following procedure.
1. As superuser on the main SSP, run ssp_backup (1M) to create an archive of your SSP environment.
2. Remove the following files to reduce the size of the data synchronization backup created before you run setdatasync backup :
$SSPLOGGER/messages. x
$SSPLOGGER/ domain /Edd- recovery_files
$SSPLOGGER/ domain /messages. x
$SSPLOGGER/ domain /netcon. x
$SSPLOGGER/ domain /post/ files
where x is the archive number of the file. Because these files are propagated from the new main SSP to the spare after a failover, you must remove these files on both the main and spare SSP to prevent regeneration of these files.
Use the showdatasync (1M) command on the main SSP to obtain basic status information about data synchronization. The examples in this section show the different types of information displayed by the showdatasync command. For additional details, see the showdatasync (1M) man page.
The next example shows the file propagation status of the data synchronization process, the file currently propagated (none), and the number of files queued for data propagation (none). In this case, the status ACTIVE ARCHIVE indicates that a data synchronization backup is being performed.
The following example shows the file propagation status of the data synchronization process, the name of the file currently being propagated, and the number of files queued for data propagation (none). In this case, the status ACTIVE indicates that the data synchronization process is enabled and functioning normally. The data synchronization backup file is the active file currently propagated.
The next example shows a data propagation list. Note that the INTERVAL indicates the frequency, in minutes, at which the file is to be checked for changes, as part of the data synchronization process.
ssp% showdatasync -l TIME PROPAGATED INTERVAL FILE Mar 23 16:00:00 60 /tmp/t1 Mar 23 17:00:00 120 /tmp/t2 |
The example below shows the files queued for data synchronization:
Command synchronization recovers user-defined commands that are interrupted by a failover and automatically reruns those commands on the new main SSP after a failover. Command synchronization does the following:
Maintains a command synchronization list on the spare SSP that specifies the commands to be restarted after a failover. Each command is run as user ssp .
After a failover, reruns specified user commands.
After a failover, resumes processing of specified user scripts from certain marked points (that you identify within each script).
These user scripts must be structured so that processing can be resumed from a labeled marker point in the script.
If you want user commands to be automatically recovered after a failover, you must prepare these user commands for synchronization as explained in the following sections.
The runcmdsync (1M) command prepares a user command for automatic restart. runcmdsync adds the user command to the command synchronization list, which identifies the commands to be rerun after a failover.
As user
ssp
on the main SSP, type:
script_name is the name of the user command to be restarted.
parameters are the options associated with the specified command.
The specified command will be rerun automatically on the new main SSP after a failover.
If you want to resume processing of a user script from a certain marked point (location) within the script, you must include the following synchronization commands in the user script:
initcmdsync (1M) creates a command synchronization descriptor that identifies a particular script and its associated data.
These descriptors are placed in a command synchronization list that determines which user scripts are to be restarted after an automatic failover.
savecmdsync (1M) specifies a marker point from which the script can be restarted.
cancelcmdsync (1M) removes the command synchronization descriptor from the command synchronization list.
Each script must contain the initcmdsync and cancelcmdsync commands to initialize the script for synchronization and then remove the command from the command synchronization list respectively. For details on the synchronization commands, see the cmdsync (1M) man page.
The following procedures describe how to use these synchronization commands.
1. In your user script, type the following to create a command synchronization descriptor that identifies your script:
script_name is the name of the script.
parameters are the options associated with the specified script.
The output returned from the initcmdsync command serves as the command synchronization descriptor.
1. In your user script, type the following to mark an execution point from which processing can be resumed:
identifier is a positive integer that marks an execution point from which the script can be restarted.
cmdsync_descriptor is the command synchronization descriptor output by the initcmdsync command.
1. In your user script, type the following after the script termination sequence:
where cmdsync_descriptor is the command synchronization descriptor output by the initcmdsync command. The specified descriptor is removed from the command synchronization list so that the user script is not run on the new main SSP after a failover.
Use the showcmdsync (1M) command on the main SSP to review the command synchronization list that identifies the user commands to be restarted on the new main SSP after an automatic failover.
The following is an example command synchronization list output by the showcmdsync (1M) command:
For further details, see the showcmdsync (1M) man page.
SSP provides an example user script that shows how the synchronization commands can be used. This script is located in the /opt/SUNWssp/examples/cmdsync directory. This directory also contains a README file that explains how the script works.
After an SSP failover occurs, you must perform certain recovery tasks:
Identify the failure point or condition that caused the failover and determine how to correct the failure.
Depending on the failover condition, note that a failover is either initiated or disabled. To identify the failure point, use the showfailover (1M) command to review the failover state and connection status. Review the connection map in the showfailover output and the summary of the failover detection points in Chapter 10 .
You can also review the platform log file to review other error conditions and determine the corrective action needed to reactivate the failed components.
After resolving the problem, re-enable SSP failover using the setfailover (1M) command (see To Enable SSP Failover ).
Rerun any SSP commands that were interrupted by a failover, with the exception of the DR commands addboard (1M), deleteboard (1M), and moveboard (1M), which are automatically resumed on the new main SSP.
|
Sun Enterprise
10000 SSP 3.5 User Guide
| 816-3624-10 |
|
Copyright © 2002, Sun Microsystems, Inc. All rights reserved.
