


Creating and Using Threads
The threads packages will cache the threads data structure and stacks so that the repetitive creation of threads can be reasonably inexpensive.
However, creating and destroying threads as they are required is usually more expensive than managing a pool of threads that wait for independent work.
A good example of this is an RPC server that creates a thread for each request and destroys it when the reply is delivered, instead of trying to maintain a pool of threads to service requests.
While thread creation has less overhead compared to that of process creation, it is not efficient when compared to the cost of a few instructions. Create threads for processing that lasts at least a couple of thousand machine instructions.
Lightweight Processes
Figure 9-1 illustrates the relationship between LWPs and the user and kernel levels.
Figure 9-1 Multithreading Levels and Relationships
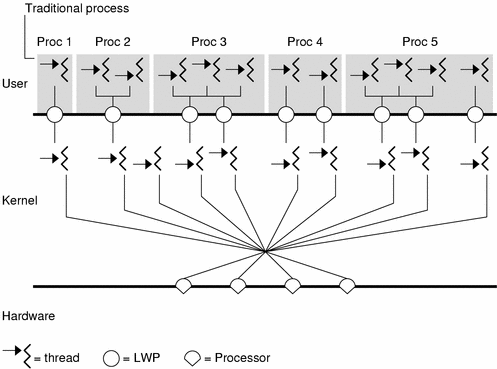
The user-level threads library ensures that the number of LWPs available is adequate for the currently active user-level threads. The operating environment decides which LWP should run on which processor and when. It has no knowledge about user threads. The kernel schedules LWPs onto CPU resources according to their scheduling classes and priorities.
Each LWP is independently dispatched by the kernel, performs independent system calls, incurs independent page faults, and runs in parallel on a multiprocessor system.
An LWP has some capabilities that are not exported directly to threads, such as a special scheduling class.
The new threads library introduced in Solaris 9 actually assigns one LWP to every thread. This is the same as the alternate libthread in Solaris 8.
The new implementation solves many problems that were inherent in the design of the old threads library, principally in the areas of signal handling and concurrency. The new threads library does not have to be told the desired degree of concurrency via thr_setconcurrency(3THR) because every thread executes on an LWP.
In future Solaris releases, the threads library might reintroduce multiplexing of unbound threads over LWPs, but with the constraints currently in effect for Solaris 9:
all runnable threads are attached to LWPs
no hidden threads are created by the library itself
a multithreaded process with only one thread has semantics identical to the semantics of a traditional single threaded process.
Unbound Threads
The library invokes LWPs as needed and assigns them to execute runnable threads. The LWP assumes the state of the thread and executes its instructions. If the thread becomes blocked on a synchronization mechanism, the threads library may save the thread state in process memory and assign another thread to the LWP to run.
Bound Threads
Bound threads are guaranteed to execute on the same LWP from the time the thread is created to the time the thread exits.
Thread Creation Guidelines
Here are some simple guidelines for using threads.
Use threads for independent activities that must do a meaningful amount of work.
Use bound threads only when a thread needs resources that are available only through the underlying LWP, such as when the thread must be visible to the kernel, as in realtime scheduling.
Working With Multiprocessors
Multithreading lets you take advantage of multiprocessors, primarily through parallelism and scalability. Programmers should be aware of the differences between the memory models of a multiprocessor and a uniprocessor.
Memory consistency is directly interrelated to the processor interrogating memory. For uniprocessors, memory is obviously consistent because there is only one processor viewing memory.
To improve multiprocessor performance, memory consistency is relaxed. You cannot always assume that changes made to memory by one processor are immediately reflected in the other processors' views of that memory.
You can avoid this complexity by using synchronization variables when you use shared or global variables.
Barrier synchronization is sometimes an efficient way to control parallelism on multiprocessors. An example of barriers can be found in Appendix B, Solaris Threads Example: barrier.c.
Another multiprocessor issue is efficient synchronization when threads must wait until all have reached a common point in their execution.
Note - The issues discussed here are not important when the threads synchronization primitives are always used to access shared memory locations.
The Underlying Architecture
When threads synchronize access to shared storage locations using the threads synchronization routines, the effect of running a program on a shared-memory multiprocessor is identical to the effect of running the program on a uniprocessor.
However, in many situations a programmer might be tempted to take advantage of the multiprocessor and use "tricks" to avoid the synchronization routines. As Example 9-5 and Example 9-6 show, such tricks can be dangerous.
Understanding the memory models supported by common multiprocessor architectures helps to understand the dangers.
The major multiprocessor components are:
The processors themselves
Store buffers, which connect the processors to their caches
memory, which is the primary storage (and is shared by all processors).
In the simple traditional model, the multiprocessor behaves as if the processors are connected directly to memory: when one processor stores into a location and another immediately loads from the same location, the second processor loads what was stored by the first.
Caches can be used to speed the average memory access, and the desired semantics can be achieved when the caches are kept consistent with one another.
A problem with this simple approach is that the processor must often be delayed to make certain that the desired semantics are achieved. Many modern multiprocessors use various techniques to prevent such delays, which, unfortunately, change the semantics of the memory model.
Two of these techniques and their effects are explained in the next two examples.
"Shared-Memory" Multiprocessors
Consider the purported solution to the producer/consumer problem shown in Example 9-5.
Although this program works on current SPARC-based multiprocessors, it assumes that all multiprocessors have strongly ordered memory. This program is therefore not portable.
Example 9-5 The Producer/Consumer Problem--Shared Memory Multiprocessors
When this program has exactly one producer and exactly one consumer and is run on a shared-memory multiprocessor, it appears to be correct. The difference between in and out is the number of items in the buffer.
The producer waits (by repeatedly computing this difference) until there is room for a new item, and the consumer waits until there is an item in the buffer.